Abstract
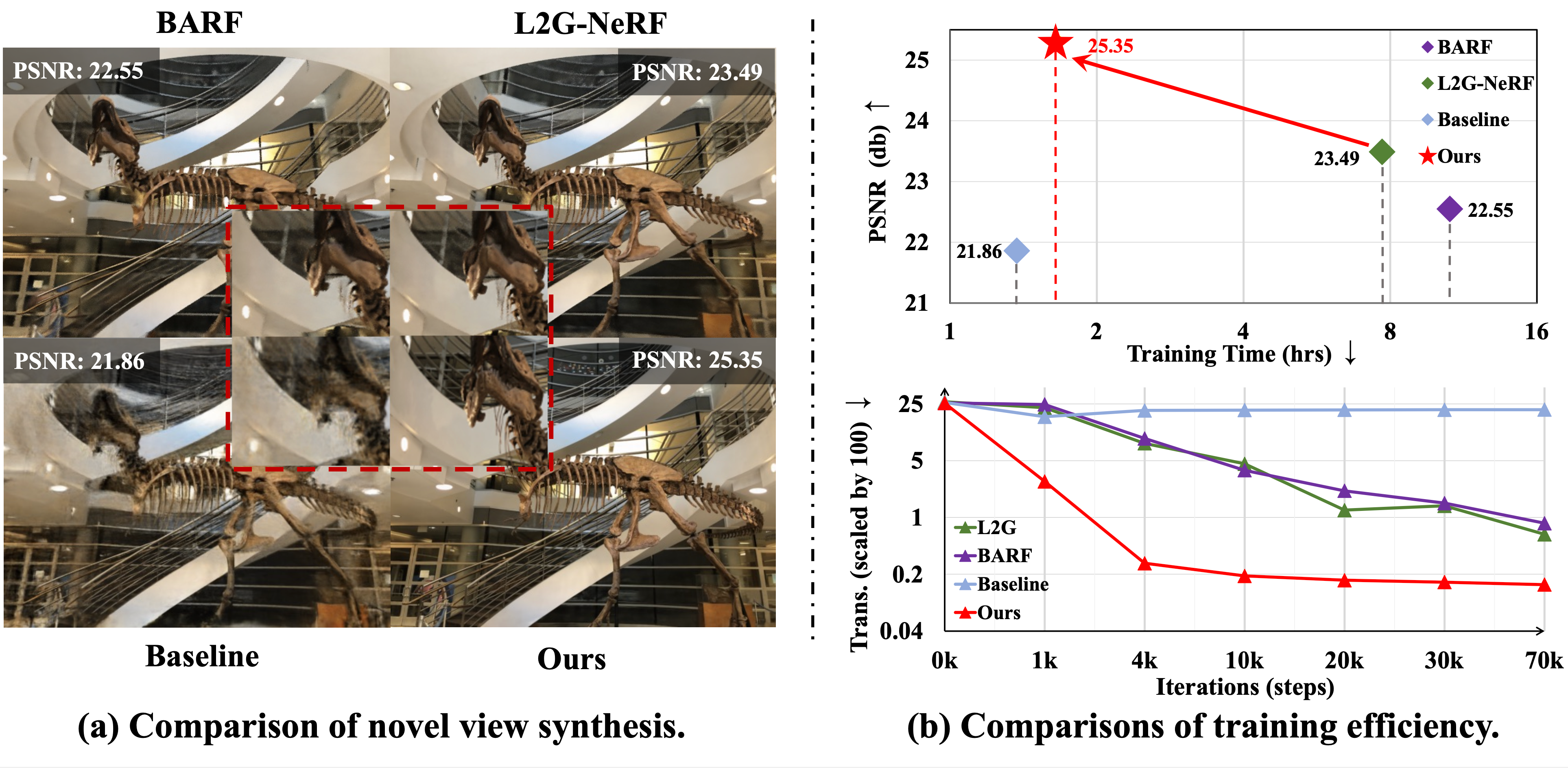
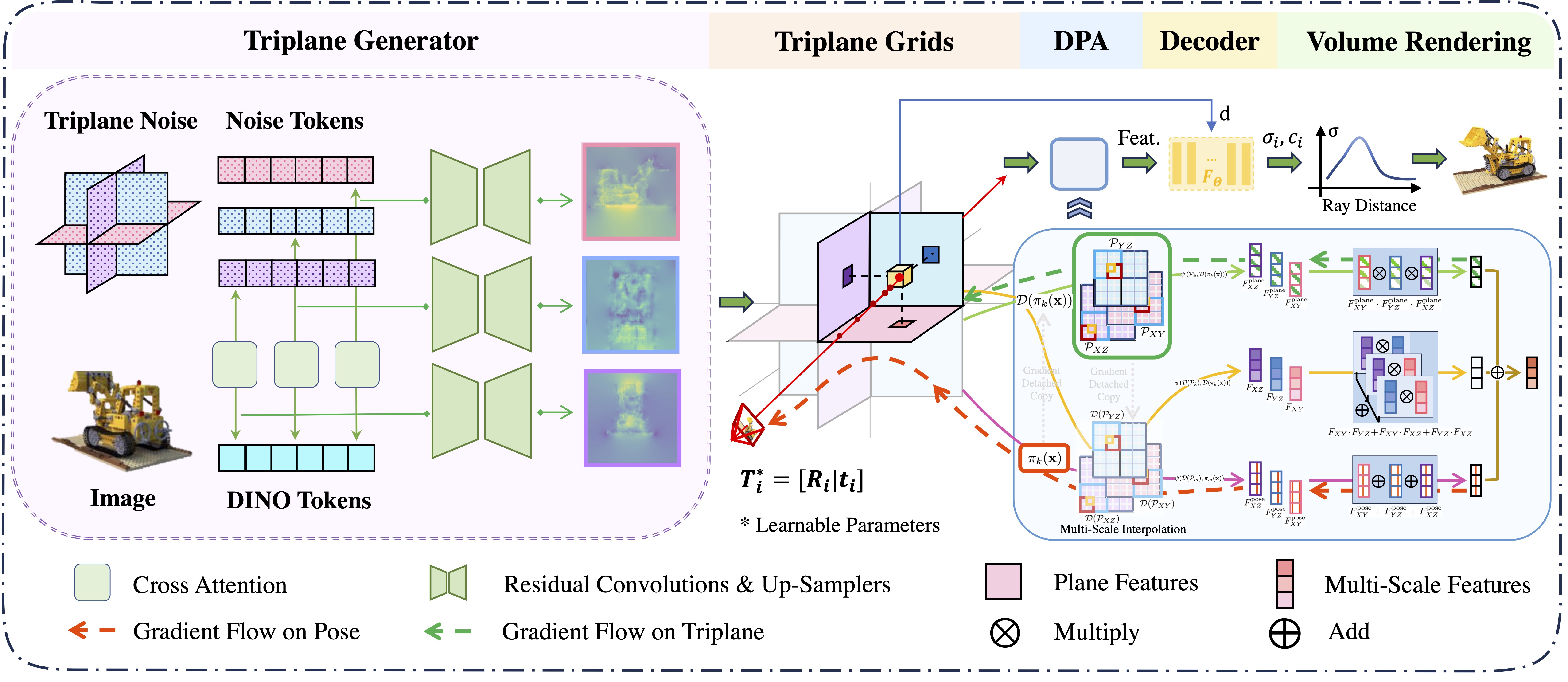
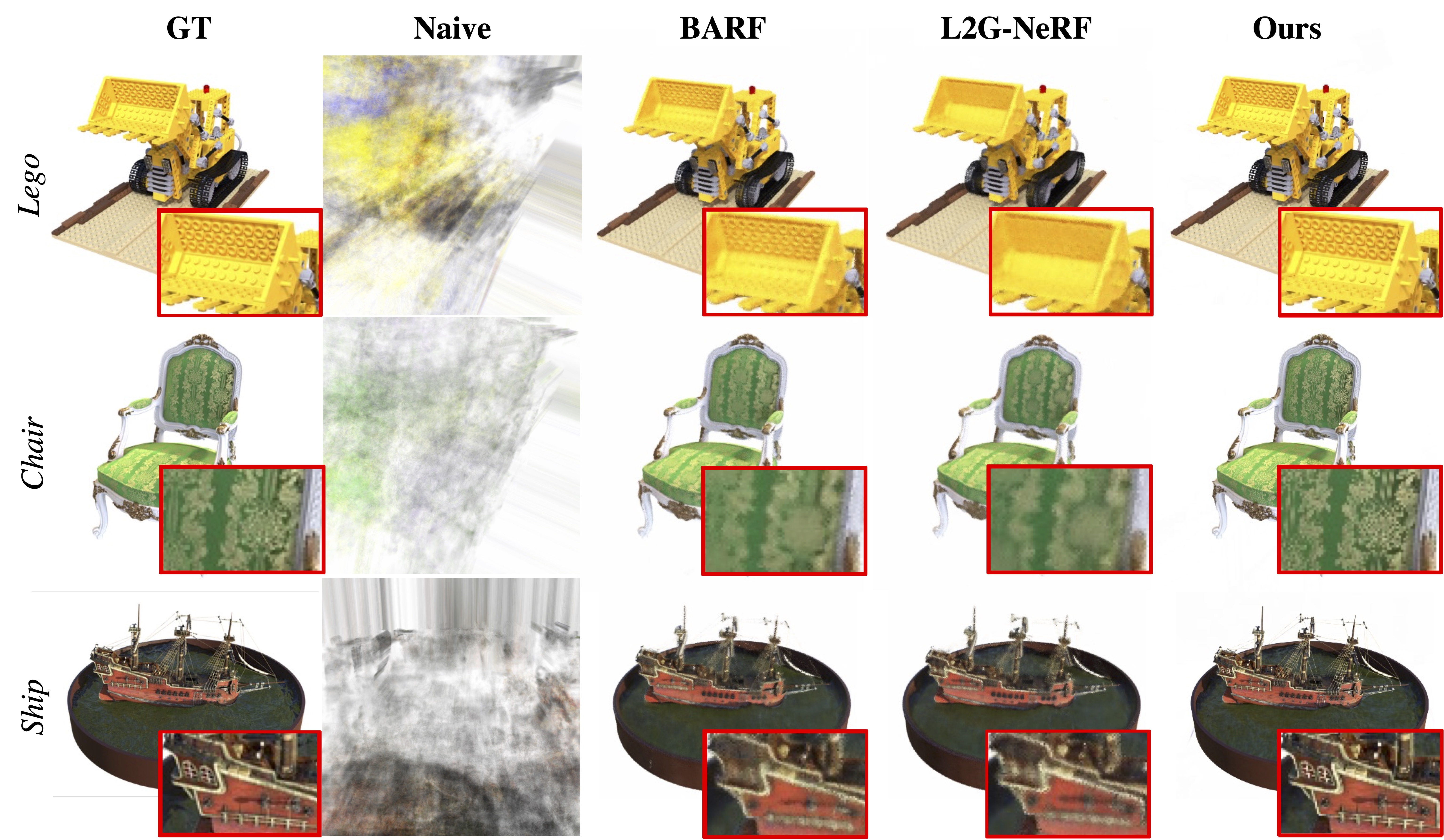
The utilization of the triplane-based radiance fields has gained attention in recent years due to its ability to effectively disentangle 3D scenes with a high-quality representation and low computation cost. A key requirement of this method is the precise input of camera poses. However, due to the local update property of the triplane, a similar joint estimation as previous joint pose-NeRF optimization works easily results in local-minima. To this end, we propose the Disentangled Triplane Generation module to introduce global feature context and smoothness into triplane learning, which mitigates errors caused by local updating. Then, we propose the Disentangled Plane Aggregation to mitigate the entanglement caused by the common triplane feature aggregation during camera pose updating. In addition, we introduce a two-stage warm-start training strategy to reduce the implicit constraints caused by the triplane generator. Quantitative and qualitative results demonstrate that our proposed method achieves state-of-the-art performance in novel view synthesis with noisy or unknown camera poses, as well as efficient convergence of optimization.